Ya he comentado alguna vez en este blog que a veces es mejor no saber estadística que saber poca estadística. Que no se me entienda mal: la estadística es una herramienta poderosísima. Sin embargo aplicar mal técnicas estadísticas puede conducirnos al error y a algo que tal vez sea peor: a una falsa sensación de seguridad en nuestras afirmaciones. Obtener coeficientes "estadísticamente significativos al 99%" puede inducirnos a afirmar solemnes tonterías creyendo que los datos nos amparan.
Recientemente, y gracias a Josu Mezo (@malaprensa) descubrí un ejemplo maravilloso que ojalá me hubieran mostrado en clase: el cuarteto de Anscombe.
El cuarteto en cuestión no es un cuarteto de cuerda sino un ejemplo de cuatro conjuntos de datos que el estadístico Anscombe inventó para tratar de convencer a sus colegas de los años 70 de la importancia del análisis visual o gráfico de los conjuntos de datos. El artículo original puede encontrarse aquí.
¿Y en qué consiste el ejemplo?. Pues bien, hay cuatro series de datos que cumplen lo siguiente:
Número de observaciones (n): 11
Media de la variable x: 9.0
Desviación típica de la variable x: 3.32
Media de la variable y: 7.5
Desviación típica de la variable y: 2.03
Coeficiente de correlación lineal: 0.816
Ecuación de regresión lineal: y = 3 + 0,5 · x
Suma de cuadrados de los residuos: 13,75 (con 9 grados de libertad)
Error estándar del parámetro b1: 0,118
R-cuadrado: 0,667
Los cuatro conjuntos de datos aparentan pues ser muy similares, pero sin embargo, cuando miramos los gráficos de dispersión vemos que hay algo patológico en los análisis de regresión en al menos tres de ellos:

El primer conjunto de datos (arriba a la izquierda) muestra una recta de regresión aparentemente normal. Los puntos quedan por encima y por debajo de la linea de forma aparentemente aleatoria.
 El segundo conjunto (arriba a la derecha) es un claro ejemplo de especificación funcional errónea. Un análisis de residuos nos daría una gráfica como la que se ve a la izquierda, lo que nos debería indicar que algo no funciona bien. Los datos x e y se ajustan muy bien a lo que parece ser una parábola, y no una recta. Probablemente un ajuste cuadrático del tipo
El segundo conjunto (arriba a la derecha) es un claro ejemplo de especificación funcional errónea. Un análisis de residuos nos daría una gráfica como la que se ve a la izquierda, lo que nos debería indicar que algo no funciona bien. Los datos x e y se ajustan muy bien a lo que parece ser una parábola, y no una recta. Probablemente un ajuste cuadrático del tipo
y = b0 + b1·x + b2·x^2
daría un ajuste mucho mejor.
El tercer conjunto de datos es un caso típico en el que aparece un punto palanca, esto es, una observación atípica e influyente que modifica sustancialmente los parámetros estimados. De no existir el punto "desalineado" la ecuación de regresión sería sensiblemente distinta. Para detectar valores atípicos e influyentes hay varios test como los residuos estudentizados o los DFFITS que nos señalarían numéricamente la observación anormal.
El último caso es tal vez el más aberrante. Es un caso en el que la variable x es prácticamente constante (excepto en una observación atípica e influyente como en el caso anterior). En este caso, un análisis de multicolinealidad nos señalaría un alto grado de dependencia lineal entre la constante y la variable x.
Por supuesto hay muchos más problemas potenciales en la aplicación "a ciegas" de técnicas de estimación estadística que invalidarían o limitarían el alcance de cualquier conclusión que pretendamos dar por válida (heterocedasticidad, multicolinealidad, no-normalidad, problemas de especificación funcional, aplicación de técnicas incorrectas dada la naturaleza de los datos... ). La estadística es como la nitroglicerina: extraordinariamente efectiva pero si no se maneja con precaución puede explotarte en las manos.
Recientemente, y gracias a Josu Mezo (@malaprensa) descubrí un ejemplo maravilloso que ojalá me hubieran mostrado en clase: el cuarteto de Anscombe.
El cuarteto en cuestión no es un cuarteto de cuerda sino un ejemplo de cuatro conjuntos de datos que el estadístico Anscombe inventó para tratar de convencer a sus colegas de los años 70 de la importancia del análisis visual o gráfico de los conjuntos de datos. El artículo original puede encontrarse aquí.
¿Y en qué consiste el ejemplo?. Pues bien, hay cuatro series de datos que cumplen lo siguiente:
Número de observaciones (n): 11
Media de la variable x: 9.0
Desviación típica de la variable x: 3.32
Media de la variable y: 7.5
Desviación típica de la variable y: 2.03
Coeficiente de correlación lineal: 0.816
Ecuación de regresión lineal: y = 3 + 0,5 · x
Suma de cuadrados de los residuos: 13,75 (con 9 grados de libertad)
Error estándar del parámetro b1: 0,118
R-cuadrado: 0,667
Los cuatro conjuntos de datos aparentan pues ser muy similares, pero sin embargo, cuando miramos los gráficos de dispersión vemos que hay algo patológico en los análisis de regresión en al menos tres de ellos:
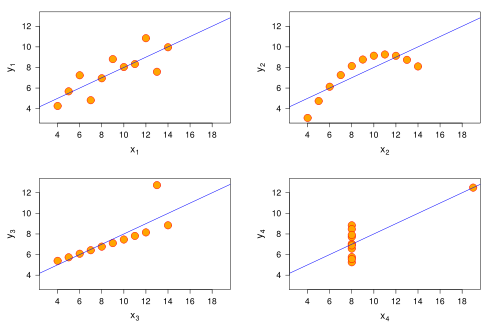
El primer conjunto de datos (arriba a la izquierda) muestra una recta de regresión aparentemente normal. Los puntos quedan por encima y por debajo de la linea de forma aparentemente aleatoria.

y = b0 + b1·x + b2·x^2
daría un ajuste mucho mejor.
El tercer conjunto de datos es un caso típico en el que aparece un punto palanca, esto es, una observación atípica e influyente que modifica sustancialmente los parámetros estimados. De no existir el punto "desalineado" la ecuación de regresión sería sensiblemente distinta. Para detectar valores atípicos e influyentes hay varios test como los residuos estudentizados o los DFFITS que nos señalarían numéricamente la observación anormal.
El último caso es tal vez el más aberrante. Es un caso en el que la variable x es prácticamente constante (excepto en una observación atípica e influyente como en el caso anterior). En este caso, un análisis de multicolinealidad nos señalaría un alto grado de dependencia lineal entre la constante y la variable x.
Por supuesto hay muchos más problemas potenciales en la aplicación "a ciegas" de técnicas de estimación estadística que invalidarían o limitarían el alcance de cualquier conclusión que pretendamos dar por válida (heterocedasticidad, multicolinealidad, no-normalidad, problemas de especificación funcional, aplicación de técnicas incorrectas dada la naturaleza de los datos... ). La estadística es como la nitroglicerina: extraordinariamente efectiva pero si no se maneja con precaución puede explotarte en las manos.
No hay comentarios:
Publicar un comentario